

Роботы, также известные как веб-пауки, а также поисковые роботы, являются важной частью процесса организации и индексации веб-страниц. Они выполняют сканирование сайтов и собирают информацию о содержимом для поисковых систем, которые затем используют эту информацию для ранжирования страниц в результатах поиска. Однако, есть случаи, когда некоторые участки вашего сайта не должны быть индексированы роботами.
Здесь на помощь приходит файл robots.txt, который позволяет веб-мастерам указывать, какие части и страницы сайта следует сканировать, а какие — нет. Файл robots.txt создается и размещается в корневой папке сайта, и прежде чем роботы начнут сканирование вашего сайта, они проверят этот файл для получения указаний.
Важно заметить, что файл robots.txt не предоставляет абсолютной защиты, и некоторые поисковые роботы могут игнорировать ваше указание. Однако многие известные поисковые системы, включая Яндекс и Google, уважают этот файл и следуют указаниям, которые вы в нем указываете.
Настройка robots.txt: что на сайте стоит спрятать от робота?
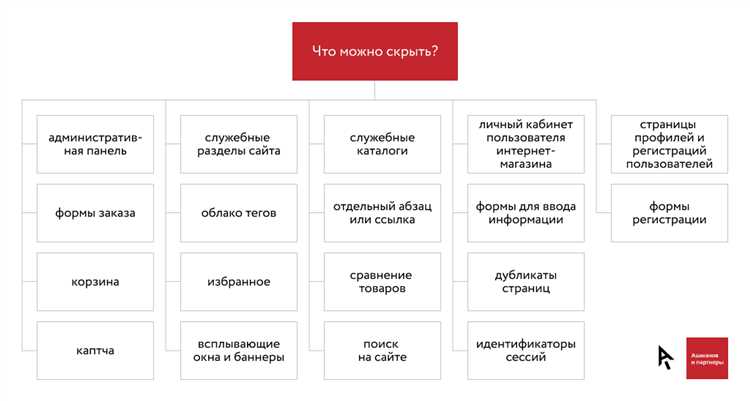
Что стоит спрятать на сайте от робота? В первую очередь, это могут быть страницы с конфиденциальной информацией, такие как личные данные пользователей или платежные данные. Также рекомендуется скрыть страницы с дублирующимся контентом, чтобы избежать негативного влияния на рейтинг сайта в поисковых системах.
- Страницы с личными данными: Многие сайты собирают личные данные пользователей, такие как электронная почта, номер телефона и адрес. Чтобы обезопасить эти данные, рекомендуется добавить в robots.txt директиву, запрещающую роботам индексировать такие страницы.
- Дублирующийся контент: Повторяющийся контент может негативно сказаться на рейтинге сайта, поэтому рекомендуется скрыть дублирующиеся страницы от роботов.
- Временные или тестовые страницы: Если у вас есть временные или тестовые страницы, которые не должны индексироваться поисковыми роботами, их также стоит скрыть в robots.txt.
Что такое файл robots.txt и зачем он нужен
Файл robots.txt имеет важное значение для оптимизации сайта и улучшения его видимости в поисковых системах. Корректная конфигурация этого файла позволяет контролировать индексацию страниц, защитить конфиденциальную информацию, предотвратить индексацию дублирующего контента и снизить нагрузку на сервер.
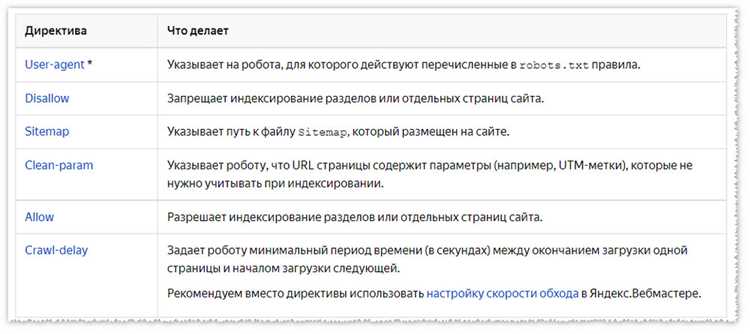
Основная цель файла robots.txt – предоставить указания роботам о том, какие страницы и каталоги сайта они должны индексировать, а какие – нет. Например, с помощью этого файла можно запретить индексацию страниц с конфиденциальной информацией, временных страниц, страниц с ошибками, а также страниц с низким качеством контента.
Некоторые примеры использования файла robots.txt:
- Запрет индексации всего сайта (/) – Disallow: /
- Запрет индексации конкретной директории – Disallow: /private/
- Запрет индексации конкретной страницы – Disallow: /login.html
- Разрешение доступа к определенному боту – User-agent: Googlebot, Disallow:
Нужно помнить, что файл robots.txt является общедоступным и доступным для каждого пользователя. Поэтому он не является мерой безопасности или средством запрета на доступ к конфиденциальной информации. Для этого следует использовать другие методы, такие как .htaccess или защита паролем.
Как создать файл robots.txt
Для создания файла robots.txt нужно открыть обычный текстовый редактор, такой как Блокнот (Notepad) или любой другой редактор, который поддерживает сохранение текстовых файлов в формате .txt. В первую очередь, вам потребуется указать базовый URL вашего сайта в следующем формате:
User-agent: *
Disallow: /example-page.html
В данном примере, мы указали, что любой робот поисковой системы (User-agent: *) не должен индексировать страницу example-page.html (Disallow: /example-page.html). В этом случае, символ «*» является шаблоном для любого робота, а «/example-page.html» – адрес страницы, которую мы хотим исключить.
После того, как вы указали все необходимые инструкции в файле robots.txt, сохраните его и загрузите на свой сервер. Не забудьте проверить правильность созданного файла с помощью различных онлайн-инструментов, которые позволяют просмотреть содержимое файла robots.txt.
Запрет на индексацию частей сайта
В файле robots.txt можно указать те разделы сайта, которые не должны индексироваться поисковыми роботами. Такой запрет может понадобиться в нескольких случаях, например:
- Конфиденциальная информация: Если на сайте присутствует страница с конфиденциальной информацией, которая не предназначена для публичного доступа, то ее индексация поисковыми системами может создать проблемы. В файле robots.txt можно указать путь к данной странице в разделе Disallow, чтобы запретить ее индексацию.
- Дубликаты контента: Если на вашем сайте есть страницы с дублирующимся контентом или дубликатами других страниц, которые не являются основными, то их индексация также может вызвать проблемы. В этом случае можно указать эти страницы в разделе Disallow.
Пример записи в файле robots.txt:
User-agent: *
Disallow: /private/
Disallow: /duplicate-page/
В данном примере указывается, что для всех роботов (User-agent: *) недоступны пути /private/ и /duplicate-page/ (Disallow: /private/, Disallow: /duplicate-page/). Таким образом, поисковые роботы не будут индексировать страницы, расположенные по этим путям.
Запрет на индексацию устаревших страниц
Процесс развития веб-сайтов часто включает создание новых страниц и постепенное удаление или изменение старых. Однако, поисковые роботы все равно могут продолжать индексировать эти устаревшие страницы, что может негативно повлиять на рейтинг сайта в поисковых системах. Для предотвращения этой проблемы можно использовать файл robots.txt.
Файл robots.txt — это текстовый файл, который располагается в корневой папке веб-сайта и указывает поисковым роботам, какие страницы нужно индексировать или не индексировать. Если владелец сайта хочет запретить индексацию устаревших страниц, он может добавить соответствующие директивы в файле robots.txt.
Пример директивы Disallow для запрета индексации устаревших страниц:
User-agent: * Disallow: /old-page.html
В данном примере мы запрещаем индексацию страницы «old-page.html» для всех поисковых роботов. Таким образом, поисковые системы будут игнорировать эту страницу и не будут ее индексировать.
Управление доступом к файлам и директориям
Для настройки доступа к файлам и директориям вам нужно знать основные правила работы с файлом robots.txt. Например, чтобы запретить роботу индексацию определенной папки, вы можете добавить следующую строку в файл robots.txt:
User-agent: * Disallow: /путь_к_папке/
В данном примере символ * означает любого робота, а /путь_к_папке/ указывает на директорию, которую вы хотите исключить из индексации. Таким образом, все файлы и подпапки, находящиеся в этой директории, не будут индексироваться поисковыми роботами.
Если вы хотите запретить индексацию конкретного файла, то нужно указать его полный путь в файле robots.txt:
User-agent: * Disallow: /путь_к_файлу.html
Такой подход позволяет управлять доступом к файлам и директориям на сайте, определять, какие данные показывать поисковикам, и предотвращать индексацию чувствительных или устаревших данных.
Ошибки, которые нужно избегать при настройке robots.txt
При настройке файла robots.txt есть несколько распространенных ошибок, которые стоит избегать. Неверная конфигурация может привести к нежелательным последствиям, таким как блокировка важного контента для поисковых роботов или раскрытие конфиденциальной информации.
1. Блокировка поисковых систем
Одной из основных целей robots.txt является предоставление инструкций поисковым роботам о том, как индексировать контент на сайте. Ошибочная настройка может привести к блокировке поисковых систем, что приведет к тому, что ваш сайт не будет отображаться в результатах поиска.
2. Неправильная блокировка контента
По сути, robots.txt предназначен для блокировки определенного содержимого от индексации. Однако, некорректная настройка может привести к неправильной блокировке контента. Например, если вы некорректно настроите параметры Disallow, вы можете случайно заблокировать весь сайт или важный его раздел.
3. Отсутствие обновлений
Как и другие файлы на вашем сайте, robots.txt должен быть обновлен при внесении изменений. Однако, многие веб-мастера забывают обновлять файл или делают это неправильно. Это может привести к нежелательным последствиям, таким как индексация конфиденциальной информации или блокировка важного контента.
4. Публикация конфиденциальной информации
Роботы поисковых систем могут просматривать содержимое файла robots.txt. Если вы ошибочно разрешите доступ к конфиденциальной информации в этом файле, она может быть раскрыта и стать доступной для поиск в сети. Поэтому важно быть внимательным при настройке файла и избегать размещения в нем конфиденциальных данных.
Итог
Правильная настройка файла robots.txt может помочь вам в управлении индексацией контента на вашем сайте поисковыми системами. Однако, чтобы избежать нежелательных последствий, необходимо избегать распространенных ошибок, таких как блокировка поисковых систем, неправильная блокировка контента, отсутствие обновлений и публикация конфиденциальной информации. Будьте внимательны и тщательно проверяйте настройки вашего файла robots.txt перед его публикацией на сайте.